Significado de data mining Definición, tipos, y técnicas

Doctor en Ingeniería
Definición formal
El data mining refiere al descubrimiento de patrones en significativos volúmenes de datos, llevado al español como minería de datos, suponiendo una solución relativamente moderna. Según el enfoque que se adopte, puede pensarse como una rama de la Estadística, Inteligencia Artificial o Ciencia de Datos.
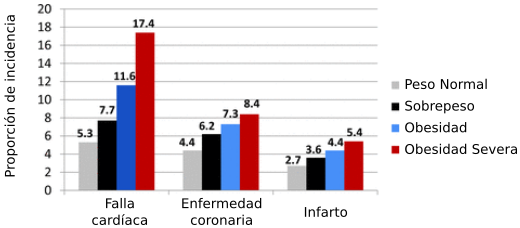
Supongamos que contamos con una base de datos médicos de un gran número de pacientes, muchos de los cuales sufren problemas cardíacos. El proceso de analizar estos datos para tratar de descubrir posibles causas o características asociadas a este tipo de enfermedades es un proceso de Data Mining. Si encontramos una relación entre, por ejemplo, el sobrepeso y el riesgo de enfermedad coronaria (como en la Figura 1, decimos que esto es Data Mining porque no se infieren las relaciones a partir de suposiciones o conocimiento. El Data Mining termina donde concluimos que la obesidad \emph{causa} estos problemas a partir de esta relación observada, pues tales conclusiones reciben ayuda del conocimiento médico.
Tipos de Data Mining
Descubrir relaciones entre dos (o más) variables no es la única tarea que se encuadra en el área del Data Mining. Hoy en día en varios ámbitos hay mucha información disponible y mucho esfuerzo volcado a la extracción de información de bases de datos, a veces, con fines cuestionables. Podemos dividir estas tareas en seis grandes tipos:
– Aprendizaje de reglas de asociación (dependency modeling): Se busca encontrar relaciones entre las variables que constituyen la base de datos. Un claro ejemplo es el que nombramos en la sección anterior.
– Detección de anomalías (outlier detecion): Aquí el objetivo es encontrar variables que se comporten de manera extraña, en el sentido de que muestren valores o asociaciones muy diferentes al resto. El objetivo de esta búsqueda puede consistir en el posterior análisis de tales anomalías (¿por qué algunos sujetos tienen presión arterial tan alta?) o bien en la eliminación de estos elementos para otros análisis (los valores registrados son imposibles, y son por lo tanto errores de medición).
– Clustering: Es el proceso de descubrir agrupamientos naturales en los datos en función de ciertas variables. El objetivo puede ser el etiquetado de grupos o de organización.
– Clasificación: consiste en asociar cada elemento de la base de datos a una etiqueta en particular, con el objetivo posterior de clasificar nuevos datos que puedan generarse. Por ejemplo, aprender a clasificar a los pacientes como «de riesgo» o no con respecto a cierta enfermedad.
– Regresión: Esta tarea consiste en encontrar una representación sencilla que modele los datos con cierto margen de error, para poder estimar las relaciones entre ciertas variables. Este concepto está fuertemente relacionado con el de dependency modelling.
– Selección o Extracción de Características: Lo que se busca es obtener una representación más compacta de los datos para ciertas aplicaciones. Por ejemplo, si queremos analizar el riesgo de enfermedad coronaria de un paciente, probablemente su color de cabello no sea muy importante.
Cabe aclarar que esta lista es una manera (entre muchas) de caracterizar estas tareas, y muchas veces vamos a encontrarnos con prácticas que no podemos clasificar exactamente en un grupo particular.
Técnicas de Data Mining
Las técnicas posibles en el espectro del Data Mining son tan variadas como sus aplicaciones, y constantemente surgen nuevas, pero podemos nombrar las más comunes:
– Regresión Lineal (Ridge o LASSO): No hace falta aclarar que es utilizada para regresión, pero permite también descubrir asociaciones entre variables.
– Máquinas de Soporte Vectorial (Support Vector Machines, SVMs): Es un método de Clasificación muy utilizado y eficiente para datos de baja dimensionalidad.
– Árboles de Decisión (y Random Forest): Pueden aplicarse a problemas de Clasificación y Clustering.
– K-medias: Quizás el algoritmo de clustering más popular.
– Redes Neuronales Artificiales: Presentan tanta variedad que podríamos decir que, según la arquitectura elegida, pueden utilizarse para cualquiera de las tareas.
Finalmente, cabe mencionar que muchas de las tareas de Data Mining pueden llevarse a cabo a través de modelos estadísticos de diferente complejidad. Más aún, casi todos los métodos aquí mencionados pueden plantearse en términos de modelos estadísticos, por lo que el concepto de Data Mining debe entenderse dentro de la misma flexibilidad y enmarcado en las mismas «zonas grises» que no nos permiten asociar los métodos de Machine Learning aquí mencionados a un único campo.
Trabajo publicado en: Feb., 2021.